Use DataLoader to Batch And Cache Arbitrary MongoDB Queries in GraphQL Resolvers
We implement arbitrary query caching and batching using DataLoader to allow greedy data fetching with automatic DB query optimization.
You may see some minimal Typescript syntax to provide some context in the example code. Do not be alarmed.
GraphQL promises a lot of cool features like the ability to batch and cache queries, save on data transmission, query for data anywhere and only request exactly what you need from the server, and all sorts of optimizations. But it merely enables these features through its use of strong typing of the API schema—they do not come for free. It’s up to us to implement the optimizations by utilizing the metadata.
Why DataLoader?
GraphQL servers require you to write resolver functions for every field, query, and schema type (implementations such as ApolloServer provide a set of default resolvers). This forces the logic for resolving data to be distributed across various resolver functions.
type User {
id: ID!
messages: [Message] # In the DB this is stored as a list of message IDs
friends: [User] # In the DB this is stored as a list of User IDs
}
const userResolvers = {
Mutation: {
createUser(root, arg, context, info) {
...
}
},
Query: {
allUsers(root, arg, context, info) {
// Fetch all users
return MongooseUserModel.find({}).exec()
}
},
User: {
messages(user, arg, context, info) {
// This function is called for every User to determine what the User.messages field value should be
return MongooseMessageModel.find({ _id: { $in: user.messages } }).exec()
},
friends(user, arg, context, info) {
// This function is called for every User to determine what the User.friends field value should be
return MongooseFriendModel.find({ _id: { $in: user.messages } }).exec()
}
}
}
If we were to call the allUsers GraphQL query, we’d get a list of Users, and for each user, the server will call the messages and friends resolver functions for each of the returned users. For every n users returned, there will be 1 + (n*2) queries! And this is for a relatively simple GraphQL schema. In a traditional REST API server you may be writing logic to handle a specific API call, and so the parameters are constrained enough for you to optimize the queries. GraphQL uses distributed resolver logic: optimizing the queries becomes almost impossible because the resolver structure is designed to handle logic for arbitrary queries and fields.
Brief Intro to DataLoader
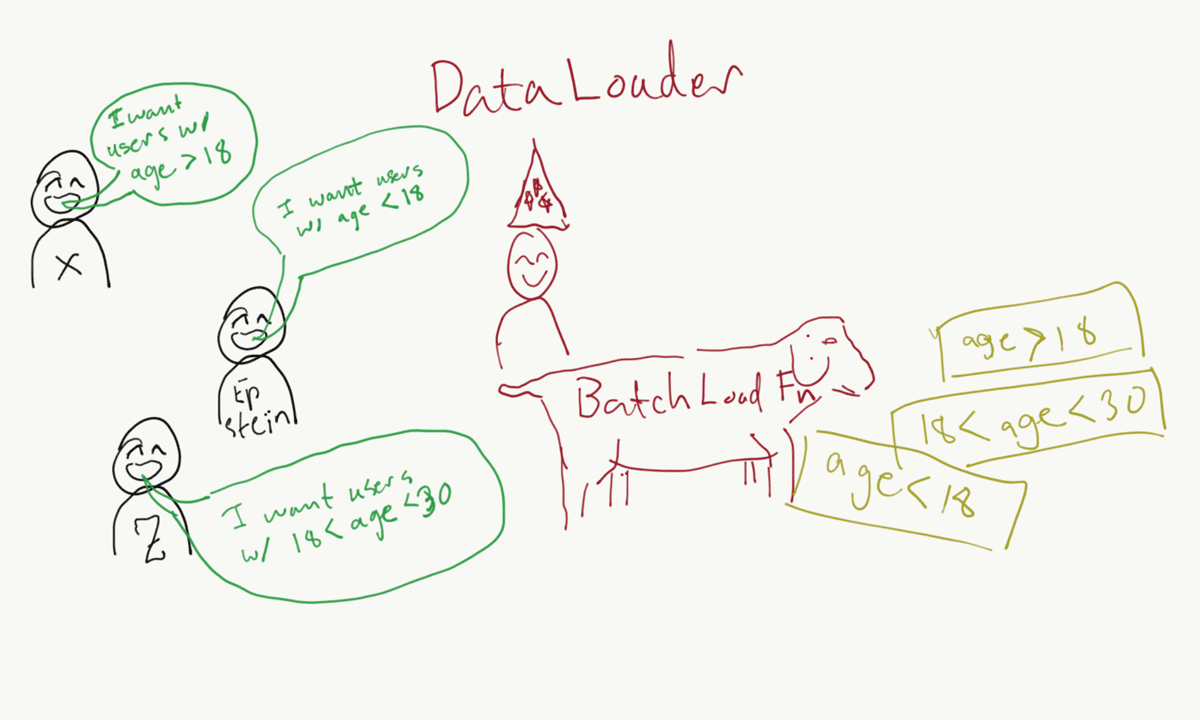
Facebook’s DataLoader project is one of those necessary implementations to optimize your GraphQL server. DataLoader doesn’t depend on GraphQL and can be used independently to batch and cache any sort of server-side data fetching, but because of the way GraphQL servers resolve data fields it’s almost required to have a production-ready server implementation. It caches queries by memoizing the primary key you are using to fetch the data. In this article I’ll demonstrate how we (at Instapainting.com) extended this to support batching any arbitrary MongoDB query—not just queries by IDs—while also preserving query caching.
If you’ve looked into the DataLoader docs you may notice that its examples revolve around optimizing queries where you find and return just one result:
// old query that we can get rid of
// const user1 = await MongooseUserModel.findOne({ _id: 1 }).exec()
// With a DataLoader you can swap out the above with this equivalent call
const user1 = await userByIDLoader.load(1)
Here the loader takes the ID “1”, makes a query with that ID implemented by the loader, and returns a single “user”.
And loading many results would require specifying a list of IDs:
This is the same as above but fires multiple “loads” all at once, returning multiple users (in the same order).
You can now call that anywhere in your code where you need to fetch a user by their ID, and as many times as you’d like. Regardless of if you call load or loadMany, all those userIDs will get sent to your batch load function. The batch load function supplied when creating the DataLoader instance is where you make your actual query with all the data at one time.
function userByIdBatchLoadFn(userIDs) {
// Remember these are batched now, so instead of "findOne" we have to do "find".
const users = await MongooseUserModel.find({'_id': { '$in': userIDs } }).exec();
// The results must be returned in the same order of the keys passed to this function
return userIDs.map((userID) => users.find((user) => user._id.toString() === userID));
}
This is a simple overview of how DataLoader works:
loader(userID) => memoize(userID) => if userID in cache, return user from cache => runQuery(listOfAllUserIDsNotInCache) => listOfUsers => loader(userID) returns a user
Memoization is the process of caching the userID so that it can pull it from cache if it exists.
DataLoader coalesces all the userIDs from a single tick of execution into a list, and you implement the actual query using that list of userIDs to return a list of users from your query (in the same order). It then handles returning the correct data to where the loader.load(userID) function was originally called. Cached lookups are returned to the correct load call, and omitted from the listOfAllUserIDs sent to your batchLoadFn when you make the actual query.
What if I want to batch a non-ID query?
This is the elephant in the room, as most queries are not just by primary keys or by IDs, and it’s not really addressed by the DataLoader docs. DataLoader requires the data key to be hashable. Thankfully, it’s not too hard to modify the default DataLoader implementation to start batching and caching arbitrary objects—in our case MongoDB queries. We just convert the object into a string!
Override the default cache function
// We use the modified stringify to normalize the query object key ordering so that {a: 1, b: 2} == {b: 2, a:1}
import stringify from "json-stable-stringify";
const dataLoaderOpts = {
cacheKeyFn: (query) => {
return stringify(query)
}
}
const usersByQueryLoader = new DataLoader(usersByQueryBatchLoadFn, dataLoaderOpts)
Now you can supply an arbitrary object to the load method.
Write your batch load function to support a list of queries
Here’s where it gets a little tricky. DataLoader expects that you return the response data in the same order in which it provides the input data. This is how it maps the responses to the input data.
When we batch a bunch of data for a MongoDB query either in the form of an $in query or by merging multiple queries with $or, the results are returned in undefined order and thus may have nothing to do with the order by which you supplied the input data in the query. It’s like everyone pooling together their food delivery order and then trying to sift through the pile of food to see who ordered what.
Don’t worry you’ll get a real artist when you order something through Instapainting.com.
db.users.query({ _id: { $in: [ 1, 2, 3 ] } }) may return data in a different order like [{ _id: 2 }, { _id: 1 }, { _id: 3 }].
In order to guarantee the data returned is in the correct order, we have to go through and match the returned data back to the original query somehow.
For simple primary key queries we just iterated the original query data and assigned the results to the right spots based on matching the primary keys:
async function userByIdBatchLoadFn(listOfUserIDs) {
const users: object[] = await ...fetch your data here...
return listOfUserIDs.map((userID) => users.find((user) => user._id.toString() === userID))
}
Since now we have a listOfQueries instead of IDs, this becomes more complicated. In the former case we start with an ID, and we end up with data which contains that same ID. In the current case we start with a query object and we end up with a list of data that has many IDs. We can longer match up query and response data using the IDs.
Which query wanted what data again?
Like a black hole emitting Hawking radiation, or mixing sperm in a test tube from multiple fathers, it’s difficult to infer the inputs from the output data. By batching the queries into one we’ve destroyed some info and it comes back to us in a disorganized pile.
The only way to associate the data to back to the caller would be:
Run the individual queries to see what data is returned for what query; compare notes.
Have some sort of one-way function that works like the ID comparison that takes a Query and checks if the data belongs to that Query.
Obviously option #1 is a no-go. The whole point of this is to avoid running all those queries! Luckily someone made option #2 already, and it’s called Sift.js.
Sift.js allows you to use the MongoDB query syntax on a regular javascript array. This is essentially option #1, but done in memory within the just the result set that was returned. To continue the food delivery analogy, this would be like simulating the job of the restaurant (MongoDB) and asking for everyone’s orders again to try to match it to the actual food in the pile on the table.
function usersByQueryBatchLoadFn(queries) {
// The '$or' operator lets you combine multiple queries so that any record matching any of the queries gets returned
const users = await MongooseUserModel.find({ '$or': queries }).exec();
// You can prime other loaders as well
// Priming inserts the key into the cache of another loader
for (const user of users) {
userByIdLoader.prime(user.id.toString(), user);
}
// Sift.js applies the MongoDB query to the data to determine if it matches the query. We use this to assign the right users to the right query that requested it.
return queries.map(query => users.filter(sift(query)));
};
Instead of returning one user per ID, the loader now returns many users per user query.
// Get back one user or undefined if no match
const user1: UserDocument | undefined = await userByIDLoader.load(1)
// Now we get back a list of potential users that matched the query, or an empty array if no matches
const users: UserDocument[] = await usersByQueryLoader.load(query)
// loadMany still works too, except you supply a list of queries for users, and get back an array of many users.
const [users1, users2]: (UserDocument[])[] = await usersByQueryLoader.loadMany([query1, query2])
There are some caveats.
Sift.js has to keep up with the official MongoDB query operator specs, and even at the time of this writing there are some MongoDB queries that don’t work. Furthermore, we’re depending on the maintainer to keep it up-to-date with spec. This would be like trying to keep up to date with the restaurant’s menu, and being able to identify someone’s order of “Lion King Roll” (actual menu item) with the correct dish sitting in front of you.
This method does not support sort or limit queries. This is because any sort params or limit params would apply to the whole batched query, rather than the individual constituent queries.
Because it doesn’t support limit queries, you should not use DataLoader for large unbounded queries (such as those where you would normally paginate).
Therefore some queries cannot be run through the DataLoader, but since DataLoading is mostly an optimization, you work with what you can get.
Putting It All Together
I’ve gone over the constituent parts of how DataLoader works and how we got it to work with arbitrary queries. Now I’ll explain how to actually tie it all together with real code.
// Assume referenced functions and symbols from earlier in this article are either defined in this file or imported
import express from "express"
const app = express()
app.get('/', async function (req, res) {
// You'll want to instantiate a new instance of DataLoader for *every HTTP request*. This is to prevent leaking data cached for one user to another user of your app.
// It doesn't have to be directly in the get() call, but must be within the call stack of this request handler
// The main goal is to *not* instantiate in the global scope for your app server
const dataLoaders = {};
dataLoaders.userByIdLoader = new DataLoader(userByIdBatchLoadFn, dataLoaderOpts)
dataLoaders.userByQueryLoader = new DataLoader(userByQueryBatchLoadFn, dataLoaderOpts)
// You can then handle your request with whatever framework you're using, and use the passed dataLoader instances to make queries
handleRequest(req, res, dataLoaders)
// Make queries like so
const oldUsers = await usersByQueryLoader.load({age: {$gte: 18}})
const youngUsers = await usersByQueryLoader.load({age: {$lt: 18}})
const specificUser = await userByIDLoader.load(12)
// Despite querying 3 times, you'll only get two queries sent to MongoDB: one for old and young users, and one for a specific user.
// And if the specificUser is one of the old or young users returned, we'd actually only get 1 query because it can be skipped due to us priming the userByIdLoader cache!
}
I’d also like to add that the technologies used here: MongoDB, Node.js, GraphQL—are not required to adopt this paradigm or put to practice these concepts. With a little modification you can make this work with SQL, Ruby, and even a REST API. Plus there are already many non-JS implementations of DataLoader available.